
Official Project-Website
|
|
(IST project IST-FET-2001-37004) Official Project-Website |
INFOMIX is a novel system
which supports powerful information integration, utilizing the ASP-system DLV. While
INFOMIX
is based on solid theoretical foundations, it is a user-friendly system,
endowed with graphical user interfaces for the average database user and
administrator, respectively. The main features of the
INFOMIX system are:
a comprehensive information model, through which the knowledge about the integration domain can be declaratively specified,
capability of dealing with data that may result incomplete and/or inconsistent with respect to global constraints,
advanced information integration algorithms, which reduce (in a sound and complete way) query answering to cautious reasoning on disjunctive Datalog programs,
sophisticated optimization techniques guaranteeing the effectiveness of query evaluation in INFOMIX,
a rich data acquisition and transformation framework for accessing heterogeneous data in many formats including relational, XML, and HTML data.
A Data Integration System offers uniform access to a set of heterogeneous sources, so that the user is freed from the knowledge about the data. The main components of a data integration systems are the Global Schema, the Source Schemas and the Mapping Assertions, as depicted below.
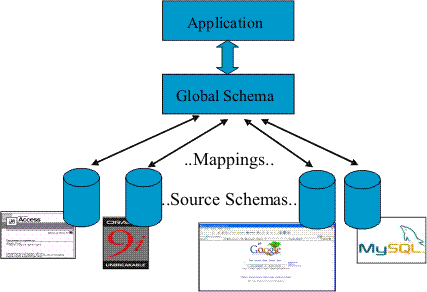
When the user issues a query over the global schema, the system:
determines which sources to query and how
issues suitable queries to the sources assembles the results, and
provides the answer
All the above tasks has to be carried out by accounting for the possibility of having both incomplete and inconsistent data. In these cases, the data retrived may be inconsistent and should be repaired.
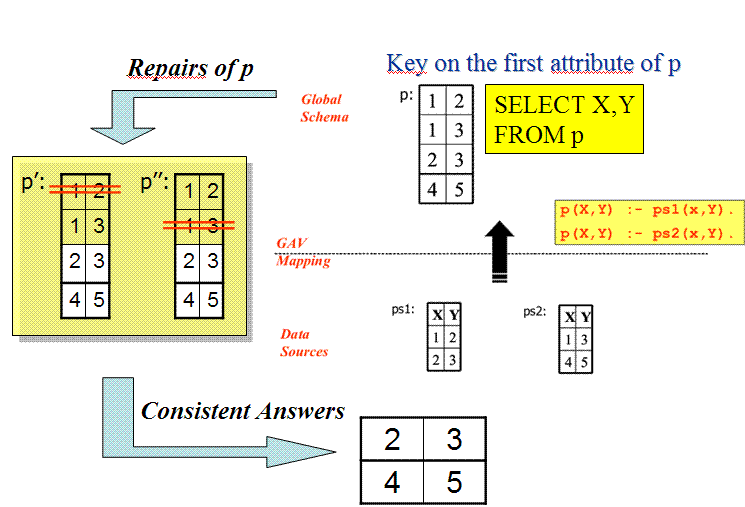
Usage of Answer-Set Programming
In INFOMIX, the setting is such that:
Queries: are UQCs
Complexity results for query answering is such setting (in the presence of incomplete and inconsistent data) are as shown in the table.
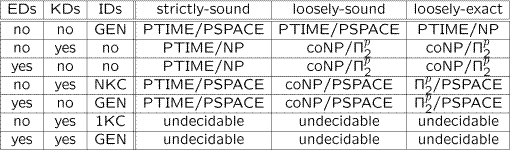
Therefore, the advanced reasoning capabilities of Answer-Set engines are really required and are exploited according to the following ideas:
Map Data Integration System specifications into logic programs under stable model semantics
Consistent query answering coincides with cautious reasoning
Answer-Set engines become the core for the computation
Benefits of Using Answer-Set Programming
The proposed approach has some attractive features. An important one is that logic programs serve as executable logical specifications of repairs, and thus provide a language for expressing repair policies in a fully declarative manner rather than in a procedural way. Furthermore, reasoning about specifications, their properties and behavior, is much better facilitated than for procedural repair specifications, since reasoning about programs is one of the principal issues in logic programming, and has been abundantly studied. Finally, extensions to the logic programming language which allow e.g. to handle priorities and weight constraints provide a useful set of constructs for expressing also more involved criteria that repairs should satisfy, which possibly have to be customized to a particular application scenario. Here, logic programming specifications may serve as a useful test-bed for development, since variants of repair can be quickly realized and experimented with.
Demo Scenario
We have tested
the INFOMIX prototype system by means of a real-life application scenario, in
which data from various legacy databases and web sources must be integrated for
a university information system. In particular, we built our information
integration system on top of the data sources available at the University of
Rome “La Sapienza”. The data sources comprise information on students,
professors, curricula and exams in various faculties of the university.
Currently, this data is dispersed over several databases in various (autonomous)
administration sources and many webpages at different servers. Given this
setting, we have devised a global schema of 14 relations,student(S ID,FirstName,SecondName,CityOfResidence,
Address,Telephone,HighSchoolSpecialization)
enrollment(S ID,FacultyName,Year)
course(C Code, Description)
. . .
and 29 integrity constraints, comprising KDs, IDs, and EDs. The application
scenario includes 3 legacy databases in relational format, comprising about 25
relations in total. The relation sizes range from a few hundred to tens of
thousands of tuples (e.g., exam data). Besides these legacy databases, there are
numerous web pages, which either provide information explicitly or through
simple query interfaces (e.g., members of a department, phone numbers etc). We
have developed a number of wrappers using LiXto tools, which
extract information from these web sources. In total, there are about 35 data
sources in the application scenario, which are mapped to the global relations
through about 20 UCQs. Each UCQ joins up to three different logical data sources.
Finally, we have formulated 9 typical queries with peculiar characteristics, which model different use cases. Students data have been encrypted for privacy reason.
Query 1
query1(D) :- student_course_plan(C,"09089903",_,_,_),plan_data(C,E,ET),course(E,D).
This query asks for the exams in the exam plan of the student with ID 09089903.
View Rewriting;
Compute Answers.
Query 2
query2(CD) :- exam_record("09089903",C,X0,X1,X2,X3,X4), course(C,CD).
This query asks for the exams done by the student with ID 09089903.
View Rewriting;
Compute Answers.
Query 3
query3(Pfn,Pln) :- teaching(_,Pfn,Pln,_).
This query asks for the names (first name and last name) of the professors that teachs a course.
View Rewriting;
Compute Answers.
Query 4
query4(Sfn,Sln,Cor,Add,Tel,Hss) :- student("09089903",Sfn,Sln,Cor,Add,Tel,Hss).
This query asks for the personal data of the student with ID 09089903. Such queries are frequently posed by university authorities whi have to contact a student.
View Rewriting;
Compute Answers.
Query 5
query5(SID,Sln,R) :- student(SID,"ZNEPB",Sln,Cor,Add,Tel,Hss), student_course_plan(SCP,SID,T,R,"APPROVATO SENZA MODIFICHE").
This query returns the information about students and their exam plans with status "APPROVATO SENZA MODIFICHE", for the students who have as first name "ZNEPB".
View Rewriting;
Compute Answers.
Query 6
query6(U) :- university(U,"ROMA").
This query asks for Universities in ROMA.
View Rewriting;
Compute Answers.
Query 7
query7(F,S) :- student(SID,F,S,"ROMA",A,T,H), student_course_plan(SCID,SID,PT,R,ST), plan_data(SCID,CID,CT), course(CID,"RETI LOGICHE").
This query retrieves the informations about students living in ROMA having RETI LOGICHE in their exam plans.
View Rewriting;
Compute Answers.
Query 8
query8(C) :- university(N,C), #count{N1:university(N1,C)} >= 2.
This query asks for cities in which at least two universities are located.
View Rewriting;
Compute Answers.
Query 9
query9(C) :- university(N,C), not UniversityInRoma(N).
UniversityInRoma(N):- university(N,"ROMA").
This query asks for cities in wich only Universities not present in ROMA are located.
View Rewriting;
Compute Answers.
Further Information
Project-Homepage: INFOMIX
page mainted by Gianluigi Greco
and Luigi Granata.